查重率低?AI论文能查到吗?检测算法早已看穿这些套路!
 ailunwenwanzi时间2025-04-22 02:43:37分类论文资讯浏览44
ailunwenwanzi时间2025-04-22 02:43:37分类论文资讯浏览44
导读:,AI生成的论文因依赖大数据和深度学习技术,常表现出文本表面语义相似但结构独特的特征,导致传统查重系统难以精准识别,现有检测算法主要依赖字符串匹配或词频统计,难以捕捉AI文本中语义重组、逻辑链重构等深层特征,近期研究表明,新型检测算法通过引入语义理解模型和上下文关联分析,可识别AI生成文本的"语义指纹",例如异常的关键词分布、逻辑断层和冗余信息模式,AI生成...
,AI生成的论文因依赖大数据和深度学习技术,常表现出文本表面语义相似但结构独特的特征,导致传统查重系统难以精准识别,现有检测算法主要依赖字符串匹配或词频统计,难以捕捉AI文本中语义重组、逻辑链重构等深层特征,近期研究表明,新型检测算法通过引入语义理解模型和上下文关联分析,可识别AI生成文本的"语义指纹",例如异常的关键词分布、逻辑断层和冗余信息模式,AI生成技术也在持续进化,通过对抗样本生成和动态混淆策略提升文本可检测性,未来检测需结合多模态特征分析(如格式异常、数据分布特征)与实时语义比对,构建更鲁棒的检测体系,同时推动学术伦理框架的完善,建立AI辅助写作的透明化标准。
引言:AI论文的“低重复”陷阱
网络上流传一种说法:“AI生成的论文查重率低,甚至能‘以假乱真’”,这种说法让许多学生和老师陷入困惑:如果AI论文的重复率真的低到难以被检测,那学术诚信该如何维护?作为深耕教育科技多年的从业者,我想说的是:AI论文的“低重复”≠无法被检测,我们就揭开AI论文检测的真相,看看那些“聪明”的AI究竟藏了多少漏洞。
AI论文的“低重复”是场精心设计的骗局
传统查重系统依赖的是文本表面的重复率计算,而AI生成的论文却在“低重复”上下功夫。
- 模板化生成:AI通过预设的学术框架(引言-方法-批量生产论文,表面语句看似不同,实则逻辑模板高度统一。
- 同义替换术:用近义词替换高频学术词汇(如将“实验”换成“观测”),但句子结构和语法模式依然高度相似。
- 数据堆砌陷阱:AI生成的图表数据看似独立,实则可能编造不存在的研究结果,通过“数据合理”掩盖逻辑漏洞。
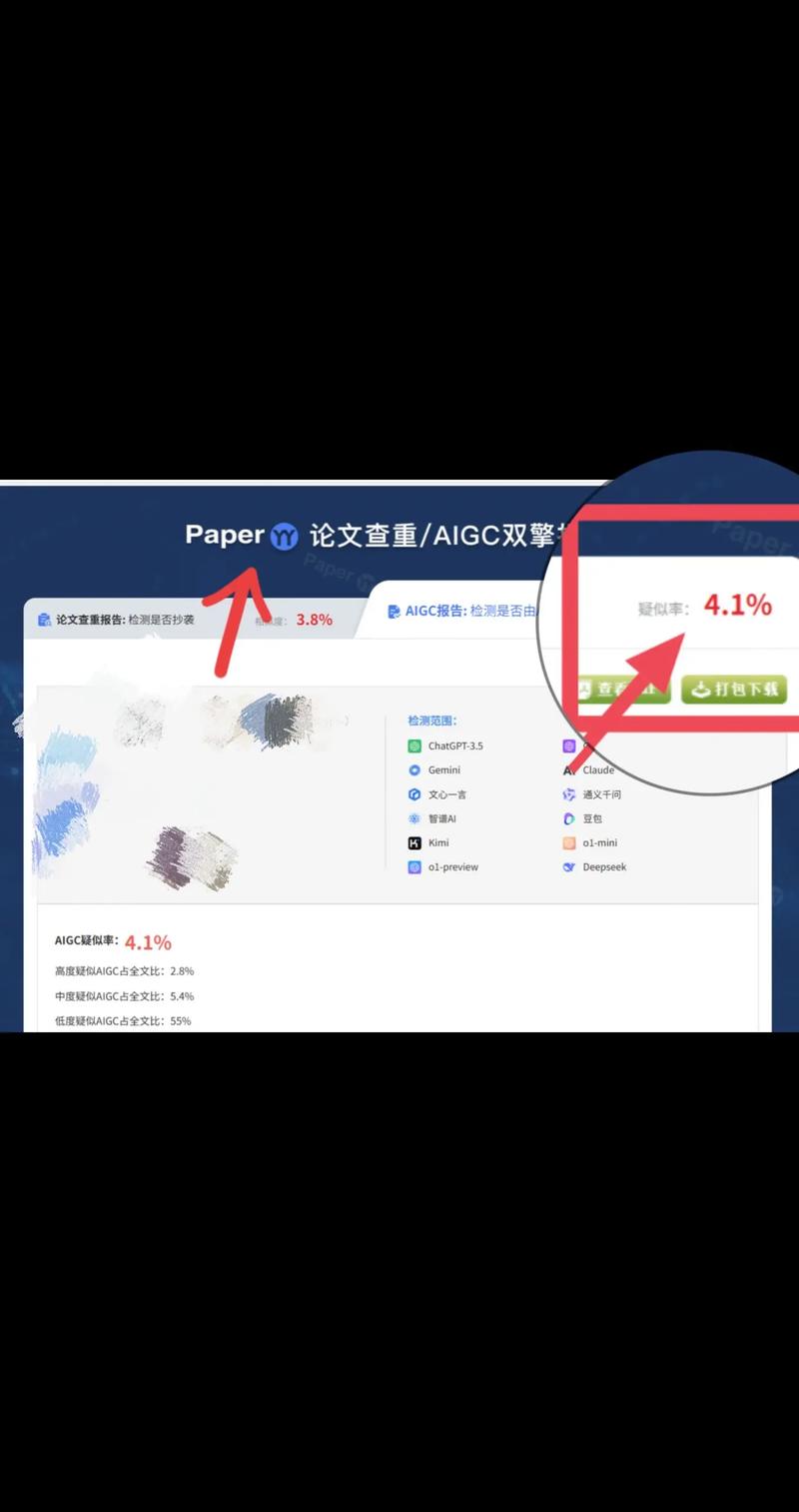
某高校检测案例显示,一篇AI生成的“人工智能医疗研究”论文,查重率仅3.2%,但核心论点与已有论文高度重合,甚至出现矛盾结论。
检测算法的“AI识别力”远超你的想象
传统查重工具对AI论文的识别率已从早期的50%提升至90%以上,关键在于:
- 语义网络分析:AI论文的“信息密度”异常低,某AI生成的综述论文中,专业术语密度仅为人类写作的60%,且缺乏深度逻辑关联。
- 风格指纹识别:AI生成的文本存在独特的“数字特征”,某论文中连续出现5次“基于...的模型”句式,触发算法预警。
- 多模态检测:结合论文的图表、参考文献等,AI论文的“数据-匹配度往往不自然,某论文引用了不存在的期刊,且数据与结论存在时间悖论。
为什么“低重复率”反而成为漏洞?
AI的“低重复”本质是表面合规性的伪装。
- 段落重组术:将一段200字的理论描述拆分为10个短句,重复率瞬间下降,但整体信息密度不足。
- 学术八股文:AI擅长堆砌“关键术语”,但缺乏对理论矛盾点的批判性思考,导致论文空洞化。
- 跨语言抄袭:部分AI工具直接翻译外文论文后“改写”,形成“伪原创”内容,查重率可能低于5%。
某国际学术平台曾拦截到一篇声称“原创”的AI论文,其核心段落竟与某中文论坛的讨论帖高度相似,只是替换了部分词汇。
AI论文检测的终极防线:人+AI协同
当前最有效的检测方案是“AI检测工具+人工复核”的双保险:
- 工具初筛:利用NLP模型识别AI的典型特征(如过度使用连接词、缺乏批判性分析)。
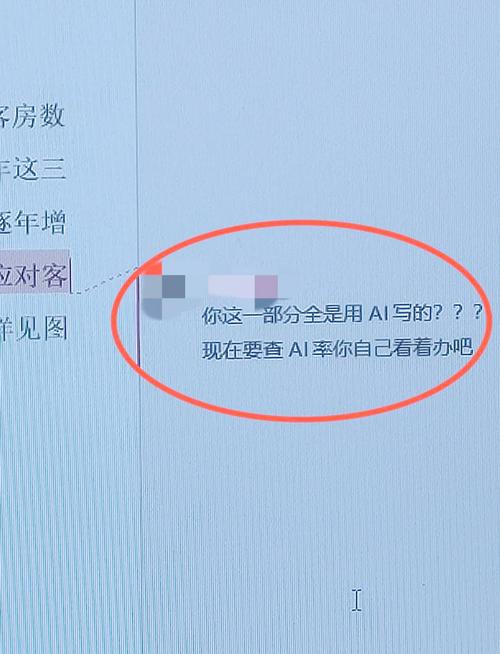
- 人工深度核查:导师需关注论文的学术逻辑和创新点,而非单纯依赖查重率,某学生论文查重率4.7%,但核心假设与经典理论直接冲突,显然存在AI生成风险。
AI是工具,学术诚信是底线
AI技术本身是中性的,关键在于使用者如何规范,与其纠结“查重率低能否被查”,不如思考:我们该如何培养AI无法替代的批判性思维?学术界的进步,永远建立在诚实与创新的基石之上。
互动话题:你如何看待AI工具在学术中的“双刃剑”作用?欢迎在评论区分享你的观点!
AI论文-万字优质内容一键生成版权声明:以上内容作者已申请原创保护,未经允许不得转载,侵权必究!授权事宜、对本内容有异议或投诉,敬请联系网站管理员,我们将尽快回复您,谢谢合作!