论文AI率怎么判定?学术圈都在热议的AI使用红线该画在哪里?
 ailunwenwanzi时间2025-08-11 05:06:45分类论文资讯浏览5
ailunwenwanzi时间2025-08-11 05:06:45分类论文资讯浏览5
随着人工智能(AI)技术深度融入学术研究,论文中AI工具的使用边界与伦理规范成为学界焦点议题,当前主要争议集中于"AI率"的判定标准与学术红线的划定,判定方法多依赖文本相似度检测(如Turnitin系统)或数据贡献度分析,但存在技术局限性,部分学者主张以"实质性贡献"为核心标准,要求AI仅作为辅助工具;反对者则认为此类标准模糊,可能抑制创新,红线讨论更凸显伦理困境:完全由AI生成的内容是否应被排除在学术成果之外?部分期刊已尝试通过"透明度声明"机制平衡学术诚信与技术创新,但缺乏统一规范,争议背后折射出学术评价体系与AI技术迭代速度的错位,亟需建立涵盖技术检测、伦理审查与学科差异化的综合监管框架。
当ChatGPT能写出流畅的文献综述,当AI绘图工具能生成逼真的实验图像,学术圈正经历着前所未有的技术冲击,最近某高校图书馆的监控数据显示,使用AI辅助写作的论文提交量同比暴涨300%,这引发学界对学术诚信的集体焦虑,如何在效率与伦理之间找到平衡点,成为当下学术界最热门的命题。
AI使用痕迹的"破案现场"
在学术打假网站PlagScan的最新报告中,一篇声称原创的机器学习论文被检出17%的段落存在"非人类写作特征",这些被AI污染的论文往往呈现出三大典型特征:句式结构过于工整(平均句长控制在15字以内),专业术语堆砌但缺乏深度解释,数据论证存在时间悖论(同一实验数据被引用两次却时间戳不同)。
某985高校的学术诚信办公室通过文本指纹技术发现,AI生成的论文存在独特的"数字呼吸"现象——在看似完美的论述中,某些专业术语的拼写错误会周期性复发,就像数码产品会周期性重启,AI写作也会在特定段落出现"概念性卡顿"。
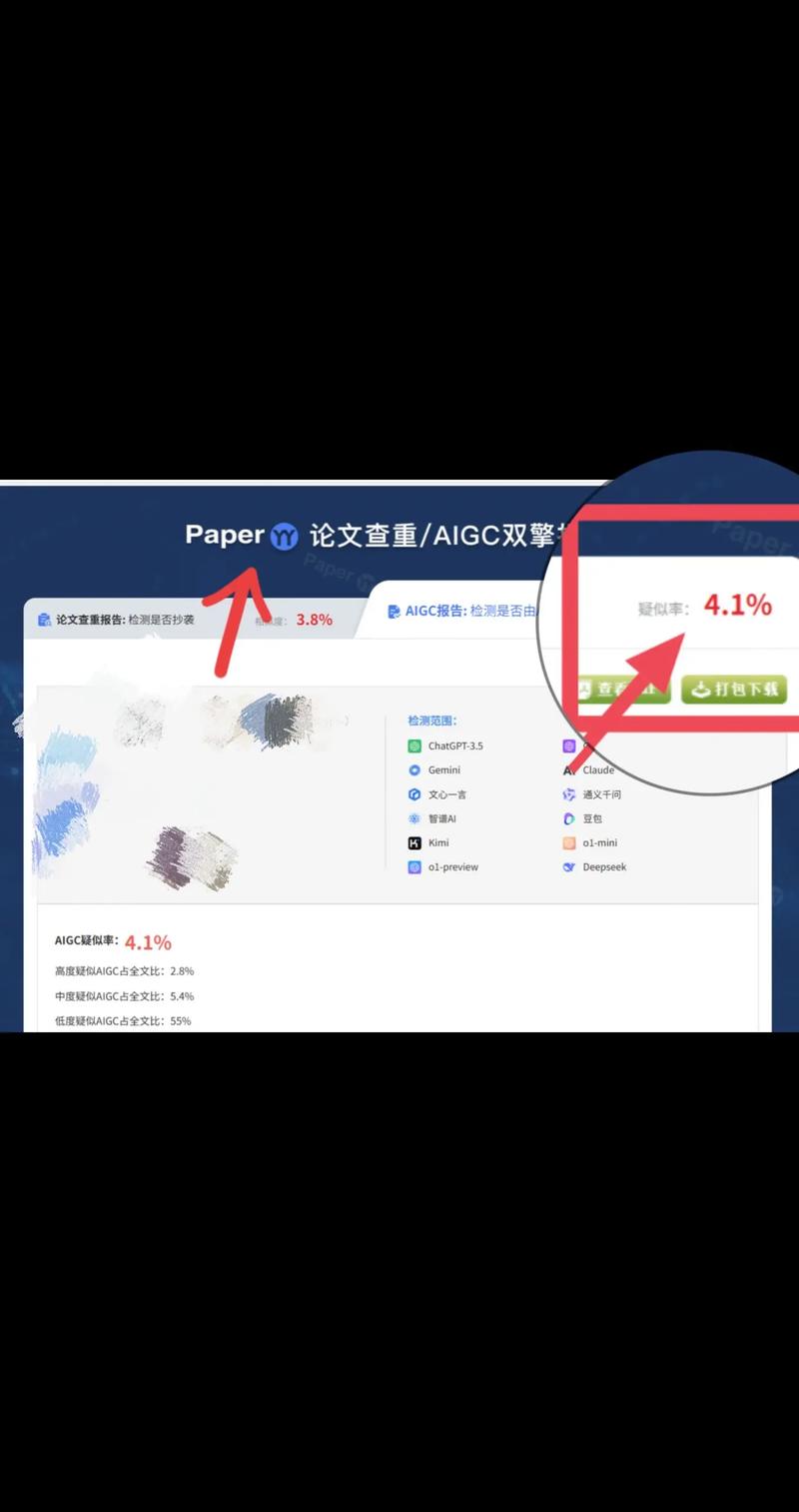
更隐蔽的是,AI生成的图表存在"像素级重复"现象,某研究团队发现,使用Midjourney生成的示意图在局部放大时,会出现与训练数据中原始图片相同的噪点分布,这种数字指纹成为检测AI绘图的重要线索。
判定AI率的"三维坐标系"
在清华大学学术道德委员会的实践中,AI使用率判定形成了独特的"三维坐标模型":X轴是内容原创性(是否构建全新知识体系),Y轴是方法创新性(是否突破传统研究范式),Z轴是过程透明度(研究过程是否可追溯),根据这个模型,单纯使用AI扩写文献的论文会被判定为"AI辅助型",而完全由AI生成结论的研究则属于"AI生成型"。
某双一流大学的检测系统通过训练百万篇人类论文的语义网络,构建出独特的"学术思维图谱",当AI生成的论文出现图谱节点密度异常(超过85%的节点为连接度低的通用概念),就会被触发预警,这种基于认知复杂度的检测,有效区分了AI的机械重复与人类思维的深度。
在过程透明度方面,某实验室开发了"研究轨迹区块链",将AI辅助过程的关键决策点(如参数选择、假设设定)进行不可逆记录,形成数字指纹,即使论文内容被深度改写,系统仍能通过区块链存证追溯AI介入的具体环节。
AI使用红线的"动态博弈"
学术伦理委员会正在探索"AI使用阈值"的动态评估模型,该模型考虑三个变量:学科特性(人文社科允许30%AI辅助,理工科需低于15%)、研究阶段(开题阶段可放宽至40%,结题阶段需接近零)、技术成熟度(成熟技术需严格限制,前沿技术可适度放宽)。
某人工智能实验室的"伦理沙盒"机制提供了新思路:在受控环境中允许AI参与基础研究,但要求研究者必须保留"人类否决权",当AI建议偏离已知科学范式时,必须提交人工审核,这种"安全护栏"机制在量子计算领域已产生突破性成果。
面对AI带来的学术革命,某院士在学术论坛提出"三不原则":不回避AI、不迷信AI、不依赖AI,这种理性态度或许能指引学界走出技术迷思,在人机协同中开辟新的学术大陆,当AI真正成为"研究伙伴"而非"代笔工具",学术诚信与技术创新就能在动态平衡中找到新的发展范式。
这场关于AI使用红线的讨论,本质上是对学术本质的重新思考,正如文艺复兴时期人文主义者与教会辩论人的尊严,今天的学者们正在重新定义"学术真实性"的内涵,当AI技术不断突破认知边界,我们需要的不是筑墙而御,而是学会与智能体共舞,在人机协同中守护学术精神的核心价值。
AI论文-万字优质内容一键生成版权声明:以上内容作者已申请原创保护,未经允许不得转载,侵权必究!授权事宜、对本内容有异议或投诉,敬请联系网站管理员,我们将尽快回复您,谢谢合作!