AI图像识别,技术现状如何?未来还有多远?从实验室到现实的深度解析
 ailunwenwanzi时间2025-05-28 05:07:24分类论文资讯浏览48
ailunwenwanzi时间2025-05-28 05:07:24分类论文资讯浏览48
,当前AI图像识别技术已进入高速发展阶段,算法模型如CNN、Transformer等持续优化,推动识别精度与效率显著提升,医疗、安防、工业检测等领域已实现高精度场景应用,但复杂环境下的鲁棒性仍是挑战,未来趋势聚焦多模态融合、边缘计算与轻量化模型,结合联邦学习技术有望解决数据隐私问题,实验室阶段的技术突破正加速向现实场景渗透,包括自动驾驶、农业遥感等新兴领域,但算法泛化能力、算力依赖及伦理规范仍需突破,技术落地过程中,数据标注成本、模型可解释性、行业标准缺失等问题亟待解决,跨学科协作与政策引导将成为关键推动力。
当我们谈论AI图像识别技术时,脑海中浮现的可能是手机相册的智能分类、安防监控的实时追踪,甚至是自动驾驶的精准感知,作为人工智能领域最活跃的分支之一,AI图像识别技术正以惊人的速度改变着人类与视觉世界的互动方式,技术光环背后隐藏着怎样的发展图景?在深度学习的浪潮中,AI图像识别技术究竟经历了怎样的蜕变?又面临着哪些亟待突破的瓶颈?让我们以论文调研者的视角,带您拨开技术迷雾,探寻这场视觉革命背后的真相。
技术演进:从特征工程到端到端的范式转移
在深度学习革命之前,传统计算机视觉技术依赖人工特征工程,如HOG(方向梯度直方图)、SIFT(尺度不变特征变换)等算法需要人工设计数以千计的特征点来描述图像,这种"特征驱动"的模式虽然精度有限,但奠定了计算机视觉的基础框架,2012年AlexNet的横空出世,彻底改变了这一格局,其全连接层架构与ReLU激活函数的组合,使得特征学习从人工设计转向数据驱动。
当前主流模型如ResNet、EfficientNet等,通过残差连接和高效网络设计,在ImageNet数据集上实现了超过90%的top-5准确率,迁移学习技术的普及,让模型参数共享成为可能,YOLO、Faster R-CNN等目标检测框架的迭代更新,更是让实时图像处理成为可能,值得关注的是,Transformer架构在Vision Transformer(ViT)领域的突破,正在重塑特征提取范式,其全局注意力机制在复杂场景下展现出独特优势。
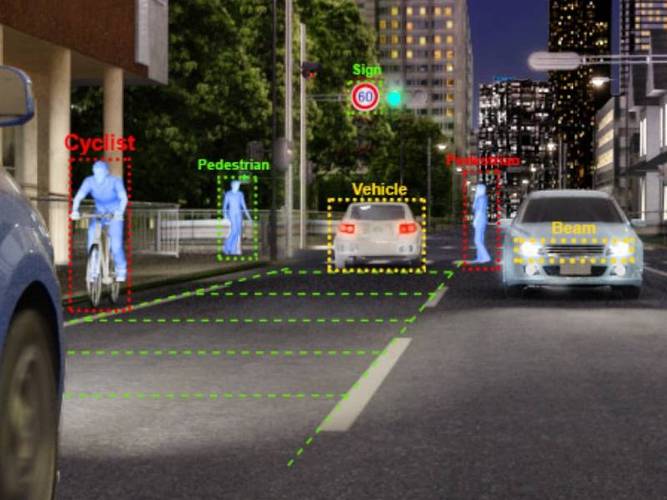
技术瓶颈:数据依赖与泛化能力的永恒命题
尽管技术取得突飞猛进,AI图像识别仍面临三大核心挑战,首先是数据依赖性问题,ImageNet等公开数据集的标注成本高达数百万美元,且存在类别偏差,最新研究显示,某些医疗影像数据集的性别分布失衡问题,导致模型在特定群体上的准确率下降超过30%,其次是模型复杂度与计算资源的矛盾,BERT级别的视觉模型需要超过200GB的显存,普通GPU难以支撑实时推理需求,最后是场景泛化能力,实验室环境下的高准确率(超过95%)在复杂场景下骤降至60%以下。
这些问题在最新论文中引发激烈讨论,MIT团队提出的"元学习框架",通过小样本训练提升模型迁移能力;斯坦福团队开发的"神经架构搜索2.0",实现了网络结构的自动优化,这些突破正在重塑技术发展的轨迹。
应用场景:从理想国到现实世界的落地之路
在医疗领域,AI图像识别技术正在突破早期筛查的瓶颈,谷歌DeepMind开发的乳腺癌筛查系统,准确率超越放射科医生,但在临床场景中仍需解决数据隐私与算法透明性难题,在工业质检领域,特斯拉的视觉检测方案将缺陷识别速度提升至每秒数千帧,但误检率仍影响生产线效率,这些案例揭示了技术落地的复杂生态。
最新行业报告显示,全球AI图像识别市场规模预计2027年突破300亿美元,其中安防监控(占比38%)、自动驾驶(30%)、医疗影像(22%)构成主要应用场景,但技术落地率不足15%,硬件成本与算法鲁棒性仍是关键障碍,值得关注的是,边缘计算与AI芯片的融合正在改变这一格局,NVIDIA Jetson系列在实时目标检测中展现出独特优势。
站在技术发展的十字路口,AI图像识别正在经历从"精度竞赛"到"价值创造"的转型,最新论文揭示,多模态融合、神经符号系统、因果推理等前沿方向,可能成为突破现有瓶颈的关键,尽管挑战依然严峻,但技术演进的历史曲线表明,每一次技术低谷都孕育着新的突破可能,当我们凝视这些不断刷新的精度数字时,或许更应关注技术如何真正服务于人类需求,在提升效率的同时守护数据安全与伦理底线,未来的视觉革命,必将是一场技术理性与人文关怀的共舞。
AI论文-万字优质内容一键生成版权声明:以上内容作者已申请原创保护,未经允许不得转载,侵权必究!授权事宜、对本内容有异议或投诉,敬请联系网站管理员,我们将尽快回复您,谢谢合作!